今天,来自中科院计算所的人工智能国家队中科视拓宣布,开源商用级SeetaFace2人脸识别算法。
SeetaFace2采用商业友好的BSD协议,这是在2016年9月开源SeetaFace1.0人脸识别引擎之后,中科视拓在人脸识别领域的又一次自我革命。
中科视拓的人脸识别技术来自于国家万人计划领军人才山世光研究员和国家自然科学基金委杰出青年基金获得者陈熙霖研究员共同领导的中科院计算所视觉信息处理与学习研究组,研究成果先后获得过国家科技进步二等奖一次和国家自然 科学二等奖一次,在行业内处于领先水平。
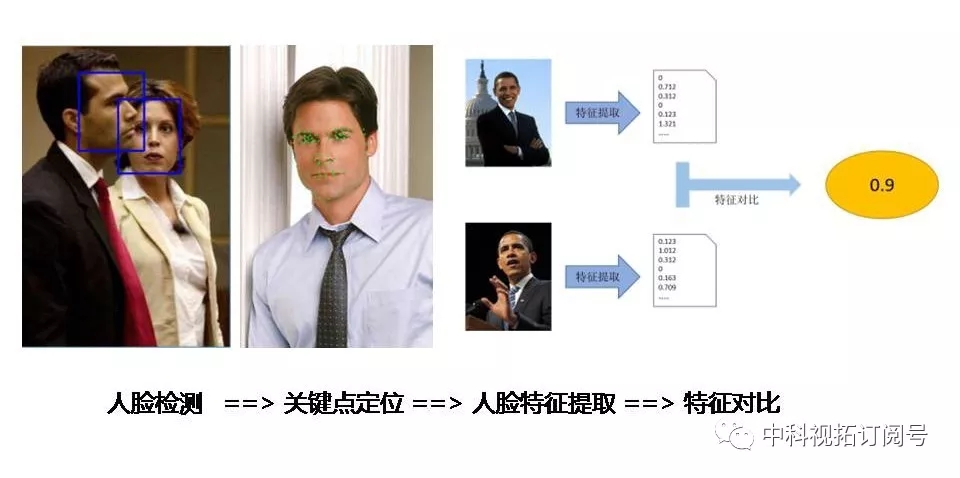
据中科视拓人脸组研发总监李凯周介绍,SeetaFace2包含了完整的人脸检测、面部关键点定位和人脸特征提取与比对模块,还将陆续开源人脸跟踪、闭眼检测等辅助模块。 SeetaFace2所有算法提供全部源代码、注释、接口文档以及样例程序,以帮助开发者快速基于SeetaFace2开发应用。
SeetaFace2采用标准C++开发,全部模块均不依赖任何第三方库,支持x86架构(Windows、Linux)和ARM架构(Android)。SeetaFace2支持的上层应用包括但不限于人脸门禁、无感考勤、人脸比对等。

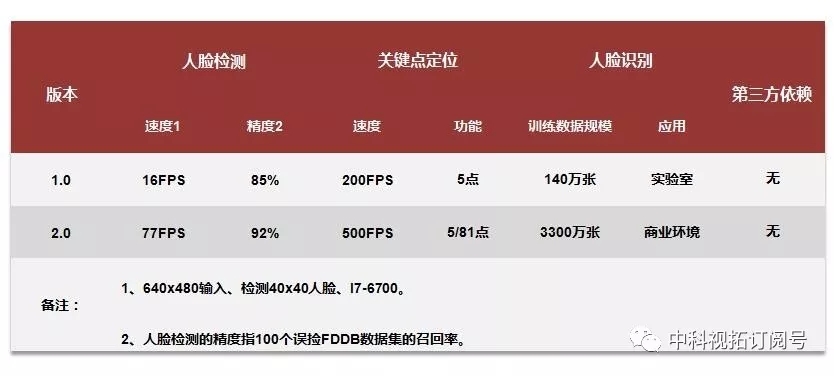
SeetaFace2是面向于人脸识别商业落地的里程碑版本,其中人脸检测模块在FDDB上的100个误检条件下可达到超过92%的召回率,面部关键点定位支持5点和81点定位,1比N模块支持数千人规模底库的人脸识别应用。

与2016年开源的SeetaFace1.0相比,SeetaFace2在速度和精度两个层面上均有数量级的提升。
知人识面辨万物,开源赋能共发展。中科视拓自成立以来,始终致力于降低AI应用门槛,赋能行业共同发展。凝聚着国内顶尖实验室技术成果的SeetaFace2的开源,将成为开发者的阶梯,产业升级的助推器,和行业伙伴一起共同推进人脸识别技术的落地。
SeetaFace2现已通过GitHub开源。(地址:https://github.com/seetafaceengine/SeetaFace2)
卷疯了卷疯了,短短十几小时内,OpenAI和谷歌接连发布核弹级成果。
国内还没睡的人们,经历了过山车般的疯狂一晚。
就在刚刚,OpenAI突然发布首款文生视频模型——Sora。简单来说就是,AI视频要变天了!它不仅能够根据文字指令创造出既逼真又充满想象力的场景,而且生成长达1分钟的超长视频,还是一镜到底那种。
Runway Gen 2、Pika等AI视频工具,都还在突破几秒内的连贯性,而OpenAI,已经达到了史诗级的纪录。60秒的一镜到底,视频中的女主角、背景人物,都达到了惊人的一致性,各种镜头随意切换,人物都是保持了神一般的稳定性。
“一名时尚女子走在充满霓虹灯和广告牌的标志性东京街头,她穿着黑色皮夹克、红长裙和黑靴子,拎着黑色手袋,戴着太阳镜,涂着红色口红,走路自信又随意。街道潮湿且反光,在灯光映射下形成镜面效果,行人走来走去。”这段60秒的视频,并非真实拍摄,而是OpenAI最新的“文生视频”模型Sora,这一段文字描述就是段Prompt(提示词)。
当地时间2月15日,人工智能(AI)巨头OpenAI宣布,正在研发“文生视频”模型Sora,可以创建长达60秒的视频,其中包含高度详细的场景、复杂的摄像机运动以及充满活力的情感的多个角色,也可以根据静态图像制作动画。OpenAI称,目前红队成员(red teamers)可以使用Sora来评估关键的危害或风险,还向一些视觉艺术家、设计师和电影制作人提供访问权限,以获取有关如何改进该模型以对创意专业人士最有帮助的反馈。
根据OpenAI官网,Sora能够生成具有多个角色、特定类型的运动以及主体和背景的准确细节的复杂场景。Sora不仅了解用户在提示中提出的要求,还了解这些东西在物理世界中的存在方式。
6个月掏出3410亿参数自研大模型,马斯克说到做到!
就在刚刚,马斯克的AI创企xAI正式发布了此前备受期待大模型Grok-1,其参数量达到了3140亿,远超OpenAI GPT-3.5的1750亿。这是迄今参数量最大的开源大语言模型,遵照Apache 2.0协议开放模型权重和架构。
Grok-1是一个混合专家(Mixture-of-Experts,MOE)大模型,这种MOE架构重点在于提高大模型的训练和推理效率,形象地理解,MOE就像把各个领域的“专家”集合到了一起,遇到任务派发给不同领域的专家,最后汇总结论,提升效率。决定每个专家做什么的是被称为“门控网络”的机制。
xAI已经将Grok-1的权重和架构在GitHub上开源。
GitHub地址:https://github.com/xai-org/grok-1?tab=readme-ov-file
目前Grok-1的源权重数据大小大约为296GB。
Grok-1是马斯克xAI自2023年7月12日成立以来发布的首个自研大模型。xAI特别强调说这是他们自己从头训练的大模型。Grok-1没有针对特定应用进行微调。xAI是马斯克去年刚刚成立的明星AI创企,其目的之一就是与OpenAI、谷歌、微软等对手在大模型领域进行竞争,其团队来自OpenAI、谷歌DeepMind、谷歌研究院、微软研究院等诸多知名企业和研究机构。 此前马斯克刚刚“怒喷”OpenAI不够“Open”,后脚这就开源了自家的顶级3410亿参数自研大模型Grok-1。虽然马斯克在预热到发布的过程中也“放了几次鸽子”,但最终他并没有食言。
今天,xAI还公布了Grok-1的更多细节:
基础模型基于大量文本数据训练,未针对特定任务进行微调。
3140亿参数的Mixture-of-Experts模型,其对于每个token,活跃权重比例为25%。
xAI从2023年10月开始使用自定义训练堆栈在JAX和Rust之上从头开始训练。
但此次xAI并没有放出Grok-1的具体测试成绩,其与OpenAI即将发布的GPT-5的大模型王者之战,必将成为业内关注的焦点。